Automating my job search with Python (Using BeautifulSoup and Selenium)

Motivation
I’m currently looking for a new data science role, but have found it frustrating that there are so many different websites, which list different jobs and at different times. It was becoming laborious to continually check each website to see what new roles had been posted.
But then I remembered; I’m a data scientist. There must be an easier way to automate this process. So I decided to create a pipeline, which involved the following steps, and to automate part of the process using Python:
1. Extract all new job postings at a regular interval
I decided to write some Python code to web-scrape jobs from the websites I was checking the most. This is what I’ll outline in this post.
2. Check the new job postings against my skills and interests
I could have tried to automate this, but I didn’t want to risk disregarding a job that may be of interest because of the criteria that I put into the code. I decided to manually review the postings that my web-scraping returned.
3. Spend one session a week applying for the new jobs that made the cut.
I have heard about people automating this stage. However, I believe chances will be better if you take the time and effort to make tailored applications, and somewhat disagree with this approach on principle.
NOTE: all code discussed in this post is available here. I’ve also shared my favourite resources for learning everything mentioned in this post at the bottom.
I decided to use BeautifulSoup and, if needed, Selenium so my import statements were the following:
Job scraping from Indeed.co.uk — using BeautifulSoup
One of the main sites I was checking for data science jobs was Indeed.co.uk.
(1) Extracting the initial HTML data
I was pleased to see that they had a standardised format for URL, which would make the web scraping easier. The URL was ‘indeed.co.uk/jobs?’ followed by ‘q=job title’ & ‘l=location’ — as below:
 |
|---|
| Searching for ‘data scientist’ jobs in London on Indeed.co.uk |
This made tailoring the job title and location pretty easy. I decided to create a function that would take in job title and location as arguments, so that I anybody could tailor the search:
Using the urlencode function from urllib enabled me to slot the arguments in to create the full url. I included ‘fromage=list’ and ‘sort=date’ within the URL, so that only the most recent jobs were displayed.
Then, with the handy help of BeautifulSoup, I could extract the HTML and parse it appropriately.
Finally, I wanted to find the the appropriate <div> that contained all of the job listings. I found this by opening the URL (indeed.co.uk/jobs?q=data+scientist&l=london_) and using the ‘Inspect’ element. Using this, I could see that <td id=“resultsCol”> contained all of the job listings, so I used soup.find(id=“resultsCol”) to select all of these jobs.
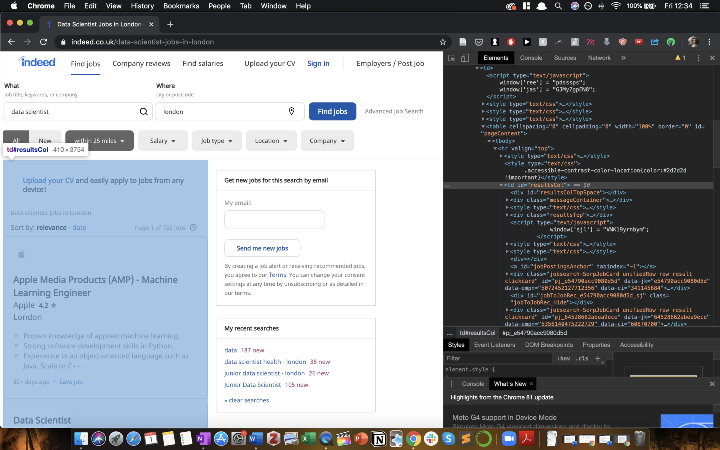 |
|---|
| Screenshot: Indeed.co.uk website |
(2) Extracting job details
Now that I had the ‘soup’ of HTML containing all the job listings, the next step was to extract the information I wanted, which were:
- The job titles
- The companies
- The link to the full job profile
- The date is was listed
For each of these, I again used Inspect to identify the appropriate section, and used the .find() function to identify them, as follows:
(3) Iterating over each job listing
Using ‘Inspect’ I saw that each job card was contained within a div with the class ‘jobsearch-SerpJobCard’, so I used BeautifulSoup’s .find_all function as follows:
Then, for each card I wanted to extract the 4 pieces of key information listed above and save them in a list.
I wanted to make my function generalisable, so that people could choose which characteristics they wanted to search for (out of job titles, companies, link and date listed), so I created a list ‘desired_characs’ to specify this.
For each characteristic, I looped over and added them to a list as follows:
Finally, I brought all of these into a jobs_list, which could then be exported to the chosen format — an Excel, DataFrame or otherwise:
Using ‘cols’ enabled me to specify the titles for each key for the jobs_list dictionary, based on the characteristics that were extracted.
‘extracted_info’ was a list of lists; each list containing, for example, all the job titles or all the companies.
Using these data structures made compiling the final jobs_list dictionary much easier.
(4) Storing and saving jobs
I converted the ‘jobs_list’ dictionary into a DataFrame and then exported it to the filename and filetype that the user selects with the following function:
(5) Integrating into a single function call
Finally, I wanted users to be do all of the above with a single function call. I did so as follows:
Satisfyingly, this produced a final result which could be called pretty easily, as follows:

Job scraping from CWjobs.co.uk — using Selenium
The next step was to generalise my script to also take in job listings from other websites. Another site I’ve been searching a lot was CWjobs. However, adding this proved more of a challenge.
When I inspected the URL, I noticed that there wasn’t a consistent pattern with the keyword arguments.
Therefore, I decided I would use a Selenium Webdriver to interact with the website — to enter the job title and location specified, and to retrieve the search results.
(1) Downloading and initiating the driver
I use Google Chrome, so I downloaded the appropriate web driver from here and added it to my working directory. I then created a function to initiate the driver as follows:
(if using an alternative browser, you would need to download the relevant driver, and ensure it has the name and location as specified above)
(2) Using the driver to extract the job information HTML ‘soup’
(3) Extracting the job information
The next step was the same as Steps 2 and 3 from the Indeed job scraping above, only tailored to CWjobs’ DOM structure, so I won’t go over it again here.
Once I finished the code, it was pretty cool seeing my web browser being controlled, without me touching the mouse or keyboard:
Wrapping up
I was pretty happy with my functioning code, and decided to stop there (I did actually have to apply for the jobs after all).
A quick search on GitHub revealed that people had already made similar job scrapers for LinkedIn Jobs and a few other platforms.
I uploaded the code to a GitHub repository with a READme incase anybody else wanted to scrape jobs using this code.
Then I sat back and felt pretty happy with myself. Now, I just run the scripts once a week, and then pick out the jobs that I want to apply for.
If I’m honest, the time and effort gains from using the script rather than doing things manually are fairly marginal. However, I had a lot of fun writing the code and got a bit more practice with BeautifulSoup and Selenium.
As a potential next step, I may set this up on Amazon Lambda, so that it does the new job search automatically once a week without me needing to. So there’s a possible future post coming on this if I do end up doing it.
I hope this was helpful/interesting!
Best resources I found while working on this project
https://realpython.com/beautiful-soup-web-scraper-python/ — a great overview / refresher on web scraping with Beautiful Soup
https://towardsdatascience.com/looking-for-a-house-build-a-web-scraper-to-help-you-5ab25badc83e — another interesting use case for a web scraper: to identify potential houses to buy
https://towardsdatascience.com/controlling-the-web-with-python-6fceb22c5f08 — a great introduction of Selenium
https://www.youtube.com/watch?v=–vqRAkcWoM — a great demo of selenium in use
https://github.com/kirkhunter/linkedin-jobs-scraper — a LinkedIn scraper, which demonstrates both selenium and beautiful soup
A video I made about this
This article was also featured in Towards Data Science here.
Comments powered by Disqus.