Machine learning in medicine in the 2020s: My thoughts
I wanted to articulate some of my current thoughts on the state of AI in medicine, so I wrote this stream-of-consciousness reflection. It’s pretty rough, and not comprehensive, so I may tidy it at some point in future.
I often see AI in medicine talked about from the perspective of ways in which it can be used; in supporting diagnosis and decision-making, improving efficiency of workflows, greater personalisation of care, accelerating research, etc.
I’m going to look at it from a different angle – by considering how it relates to the use of information. I will divide this into (i) Generation of new information, (ii) New analysis of existing information and (iii) Utilisation of information.
I will then share a few thoughts and predictions of where AI in medicine will go in the 2020s.
1. Generation of new information
Lots of the information routinely used in medicine is based around relatively simple heuristics. For example, cut off levels for many tests are defined on a population basis – natural variation will mean that ‘abnormal’ variations outside of the ‘reference range’ are actually just normal for that individual. Many models for predicting the development and progression of disease are also simplistic yet used as broad heuristics.
Machine learning can level-up these types of analysis to yield new information that can be used for supporting the diagnosis and treatment of disease. By analysing large volumes of data, it can unearth complex, nuanced relationships that enable greater personalisation of prediction as well as a higher predictive ability. Examples of this can range from predicting AKI or sepsis from many routinely collected biomarkers to predicting mortality from surgery.
Machine learning will also uncover new information by accelerating the research process itself through a number of techniques. It can accelerate drug discovery by predicting molecule interactions to identify positive and negative effects. With natural language processing, it can assimilate large quantities of existing research or lift salient information from electronic medical records. It can also amplify data available for research through automated labelling of images, for example.
I am hopeful that this means by the end of the 2020s, our clinicians will be dramatically more equipped by a far more information-rich environment.
2. New analysis of existing information
There are several types of data that were previously challenging to analyse, but that machine learning will enable.
Imaging performs a central diagnostic and prognostic role in the majority of specialties; down the “pattern recognition” spectrum, from radiology and histopathology, to dermatology and opthalmology, to cardiology, gastroenterology and respiratory medicine. Given the relative maturity of ML-based imaging techniques, it is just a matter of data availability (both quantity and quality) before imaging-based tools become widespread.
Text data represents a different type of challenge, but one where ML, perhaps on a longer time trajectory, will begin routinely yielding new information and insights. Potential uses are multitudinous – pretty much anything that may be written about in medical notes could be turned into a research question. Recent examples include assessing stroke severity and predicting emergency department outcomes.
‘Omics’ data refers to genomics, transcriptomics, proteomics and metabolomics. These are best understand with the following diagram:
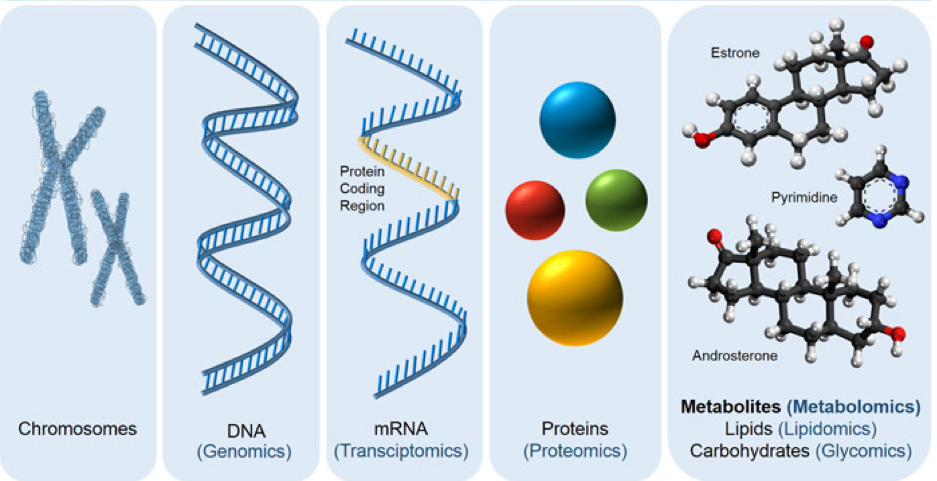
In summary, genomic information in DNA is used to create proteins, via mRNA messengers, and these proteins are built into molecules.
The interactions between these are extremely complicated, with many different molecules, which exist in many different states, interacting many different other molecules (in different ways depending on their different states). Below is a diagram of a random cell signalling pathway to help demonstrate this:
By being able to analyse large volumes of complex data, machine learning can enable us to extract meaningful information from the variations between different levels in people’s ‘omics’ data, to provide insights that are relevant to health and disease.
Finally, data from wearables, smartphones and home sensors may also be analysed using ML for meaningful health insights.
3. Utilisation of information
Chatbots, which utilise natural language processing technology, can utilise existing information in several ways. Firstly, it can increase ease of access, such as the Alexa skill that the NHS announced last year, which lets you access health information via voice. Secondly, they can be used therapeutically, such as a several ‘CBT chatbots’, which use a chatbot persona to deliver therapy using the principles of cognitive behavioural therapy. Thirdly, I believe chatbots will also have a role to play in medical education; by enabling simulated patient interactions as well as supporting learning and revision.
A key challenge, perhaps even greater than the development of ML tools themselves, is how they will be incorporated into clinical workflows. Good performance of an ML model doesn’t mean it will have a positive clinical impact, and it is important that this is assessed in a scientifically, rigorous way.
There are also several ways that ML can directly improve workflows, such as improving utilisation of theatre spaces and triaging patients in A+E. From my experience as a clinician, I believe there is huge potential for the efficiency of the health system to be improved if we are able to implement such tools ubiquitously.
So what’s next? Predictions for the next 10 years
Any prediction is going to be speculative, and has a good chance of being out by a fair margin. But this is my current sentiment:
My expectation for this decade is that we will see relatively slow and steady progress. As new datasets become available, we will develop new narrow tools which will gradually be incorporated into clinical workflows (hopefully following rigorous validation). Those providing direct financial returns (often in the form of savings) will be adopted most readily.
I believe we will continue to see many new start-ups looking to apply machine learning to healthcare, but that there will be a high failure rate among them. Common causes for failure will be insufficient advantage gained from using machine learning, and insufficient high-quality data for further development of the minimum viable product. As ‘promising’ start-ups fail, the hype around AI will dip (although not disappear entirely). I don’t think it will be either an AI summer or AI winter… I’ve heard the term AI autumn thrown around.
I believe this lull will last until a new, non-deep learning area of ML comes to the forefront and a fresh round of potential arises.
Either way, I’m excited to see what there is for me to write about at the start of the 2030s…
