Some thoughts on the role of AI in healthcare and whether AI will replace doctors

A couple of weeks ago, we published an article in the British Medical Journal reviewing research papers that evaluated AI algorithms and compared their performance with clinicians. Our main findings in the article were that the methodology of these studies leaves them prone to bias and that they often have over-stated conclusions.
I think this is an interesting springboard to consider the wider subject of what role AI is likely to play in medicine, and to consider the popular and slightly controversial question of “Will AI replace doctors?”
Here, I’m going to make the argument that: (i) AI will inevitably be able to automate some of the processes currently performed by doctors, (ii) that this will initially start in very narrow domains and gradually expand, (iii) some areas are more challenging to automate than others while other areas are out of reach entirely and (iv) they won’t replace doctors, because we won’t let them.
Note: I wouldn’t consider myself an authority on this subject, and I’m open to my opinion changing over time. This article is a reflection of my current view (as of May 2020).
Inevitable replacement of certain tasks
Within a typical day, a doctor wears many hats. Tasks can vary broadly, from eliciting information from patients, both verbally and through examination, to interpreting test results; from making diagnoses to formulating treatment plans; and from communicating with other members of the medical team to breaking bad news to relatives.
There are inevitably going to be some tasks that are simpler and more algorithmic.
Some tasks could be automated even without the need for machine learning algorithms. For example, dosing certain drugs (like warfarin) or correcting salt levels in the blood can typically be done in a rule-based way. For example, if the potassium level is below 3.5 (or in some cases, 4) and there aren’t extenuating circumstances (such as a relevant drug or past medical condition), then the potassium will be replaced in a protocolised way. There are many decisions such as these made by doctors and nurses, by following such a schema.
So why haven’t these tasks been automated already? At present, I believe the main reasons are pragmatic. Firstly, many hospitals don’t have the required information available in the same place digitally, and those that do have only done so relatively recently. Over-hauling old systems takes time and is expensive. Secondly, the responsibility must lie with someone, and having a doctor or nurse as the final sign-off on, let’s say, a prescription of potassium, provides a clear responsibility. And finally, I believe there’s a culture element; doing so would represent ceding a degree of control, and there are likely fears of the ‘slippery slope’.
I believe it is only a matter of time before these tasks become automated or near-automated (perhaps requiring a doctor/nurse sign-off), as we shift towards increasing amount of the workflow being performed in an integrated and digital way.
Then there are also more complex tasks, which may involve greater integration of information and more complex decision-making, but which ultimately are based around algorithmic, pattern-recognition. For example, spotting a diagnosis on a pathology slide or from an X-ray. There are nuances to such tasks, but given machine learning (ML)’s strength in pattern-recognition, many such specific tasks are likely to be within the technical reach of ML algorithms.
What, then, is the limit of what AI is able to achieve?
Expanding from narrow domains
Most of the health uses of AI currently being investigated are ‘narrow’ tasks; that is, they are looking to perform a singular, well-contained task. Is this image of a skin lesion benign or cancerous? Does this retinal scan show mild, moderate or severe retinopathy?
There is emerging evidence (although still early stage) that AI can perform at a comparable level to human doctors in some of these tasks and do so much faster (this was the main line of investigation of our study).
However, moving beyond these ‘narrow’ tasks becomes much more complex quite quickly. Based on this patient’s non-verbal cues, speech content and medication history, are they having a relapse of psychosis? Given this uncommon combination of two diseases, what is the appropriate balance of treatment to give? Creating pipelines for taking in these different sources of information, appropriately balancing and then integrating them represents a challenge. Creating an AI to solve these tasks may not be impossible, but it will take more time. Approaches to use combinations of different data types are being attempted, but so far typically haven’t proven very successful. For example, IBM’s Watson for Oncology aimed to integrate all available cancer patient data and disease information to guide diagnosis and therapy decisions, but was stopped early for “not meeting its goals”.
The challenges of automation
Even in tasks that appear ideal for automation with machine learning, such as ‘pattern recognition’ tasks, things are rarely that simple.
One consideration is that the different decision-making mechanisms that AI algorithms use bring the potential for unforeseen adverse outcomes. For example, while human doctors are trained to be highly aware of rare but serious conditions, an AI algorithm may be less interested if there are few such examples in the training set. Thus an algorithm may appear to perform better than a doctor, by identifying common pathologies with higher accuracy, but may inadvertently perform poorer on the more serious pathologies.
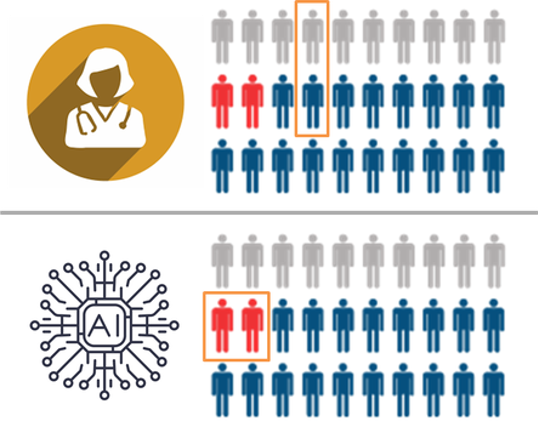 |
|---|
| Diagram key: grey = healthy, blue = unwell, red = critically unwell. Credit: Luke Oakden-Rayner |
In this hypothetical, the human and the AI have the same average performance, but the AI specifically fails to recognise the critically important cases (marked in red). The human makes mistakes in less important cases, which is fairly typical in diagnostic practice.
Another challenge is the integration of information from different pattern-recognition tasks. For example, algorithm development for imaging-based tasks often centres around finding the right diagnosis based on appearance. But in a clinical setting, a histopathologist or a radiologist will take into account a variety of other sources of information to come up with a diagnosis and treatment plan. While specialised neural networks (CNNs) may perform well at image classification, an alternative method will be required to incorporate the different sources of information appropriately.
I believe the differences in these approaches may point more towards a collaborative role, with humans and AI algorithms each covering the other’s blind spots. An early example of this is the work automating polyp detection on colonoscopy; the AI isn’t able to perform the procedure, but it is better at detecting polyps of particular shapes.
While such nuances represent technicalities, I believe that with time and intelligent, rigorous methodology to calibrate the algorithms, they can be overcome and, ultimately, will lie within the reaches of AI.
However, there are other tasks which will likely fall outside of its abilities.
The first is what I will call intuitive reasoning. I find this slightly hard to define, but I am referring to instances where we have a sense of a fact, such as a diagnosis, but don’t have a clear rationale of how we came to that conclusion. Perhaps it represents a similar pattern recognition mechanism to AI algorithms, just operating at a level below our conscious awareness. However, I think it’s also possible that it represents a different nature of decision-making which, in particular situations, may be advantageous over AI. Training an AI to replicate this type of reasoning may also be challenging; a lack of self-insight into the variables we used to make a decision may make it harder to determine the appropriate inputs and outputs to a machine learning model.
The second is in the area of social communication, particularly when involving empathy or sensitive discussion topics. Good communication can support doctors in understanding a patient’s problem, and often also forms part of the therapeutic process.
However, the extent to which this is ‘out of reach’ isn’t obvious. Humans excel at detecting subtle non-verbal cues and deciphering nuances in language, but I believe that AI algorithms can also do a pretty good job of this. For example, several studies have looked at diagnosing autism based on video recordings.
I believe the empathetic response evoked by humans is fundamentally different to that evoked by a computer. While this may enable doctors and nurses to bond more with patients, there is some suggestion that I believe the empathetic response evoked by humans is fundamentally different to that evoked by a computer. While this may enable doctors and nurses to bond more with patients, there is some suggestion that people are more willing to share sensitive information with a computer – perhaps given the lack of stigma or fear of social judgement compared to sharing such information with a human. are more willing to share sensitive information with a computer – perhaps given the lack of stigma or fear of social judgement compared to sharing such information with a human.
I think the key area out-of-reach to AI in this domain is the therapeutic role that human interaction can play. As social creatures, albeit in an increasingly digital world, we shouldn’t underestimate how important real human connection can be.
The main impediment to replacement: humans
Before we talk about replacement, we need to actually achieve superior performance and robustly demonstrate this with objective evidence. It’s worth stressing that we’re not there yet - as our study highlighted. But even as technical progress continues, and as AI is shown more robustly to be have comparable or superior performance to humans in an increasing number of specific tasks, I don’t believe that we will allow true ‘replacement’.
We have a different level of acceptance for mistakes by computers than by humans. This has often come up in discussions surrounding self-driving cars; that even if the rate of accidents is significantly lower than from human error, we won’t accept the mistakes. This reflects a wider cultural approach, which it is hard to imagine changing any time soon - particularly in healthcare.
As a result, we will be resistant to giving algorithms too much control. Using the 5-level scale initially featured in self-driving car discussions (diagram below), it is unlikely that we will progress beyond Level 2 or 3 in healthcare – a point made by Eric Topol in Deep Medicine.
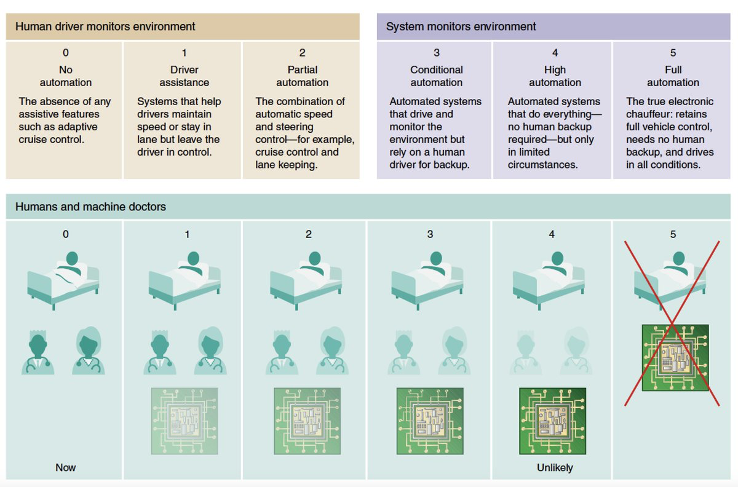 |
|---|
| Credit: Eric Topol |
One risk, however, is that we will decide not to let an algorithm replace a human task, but that it will end up doing so in practice. For example, a tool may be implemented as a ‘decision support tool’ which doctors can use to guide their actions. But if people become very confident in the algorithm, and less confident in their own abilities, the algorithm may de facto automate that decision-making process – despite us deciding we didn’t want it to.
A key aspect will be monitoring performance, as we do with other tools and models that are used in healthcare. However, there are additional challenges of AI algorithms. Performance can change as new data comes in and models are updated. There are also questions around where responsibility lies; if something goes wrong, should you blame the algorithm, or the doctor who says they followed it? Regulation will be a key guiding process in this, but we are yet to figure out how.
An interesting dynamic will occur in poorer countries with lower rates of doctors per population. In some circumstances, rather than AI vs doctor, it will be a question of AI vs no medically trained professional. This makes a stronger argument for affording greater responsibility to the algorithms.
Ultimately though, I believe in the Western world, we will try to draw a hard line in the sand around Level 2-3 of automation, and progression beyond this will face strong resistance – whether it is technically achievable or not.
Conclusion
The limits of what AI can achieve are yet to be known, and will ultimately be borne out with time and scientific investigation. For now, we have the deep learning evolution, from which it is evident that our abilities to process images, and text is much better. The degree of understanding and decision making capability that AI has remains to be seen.
I believe we will see increasing numbers of ML algorithms being developed and used over the next few years – this is already being reflected by an increase in rate of RCTs and FDA approvals. Technical capabilities will expand and we will be keen to implement, but I predict at least one case where an implemented algorithm is later realised to cause harm. This will provide fuel for the argument of a hard cap on responsibility afforded to AI algorithms, which I predict will be around Level 2, with Level 3 for a few specific conditions and scenarios.
Of course, I could be wrong. What do you think?
Suggested reading:
- Why AI won’t replace doctors but will dramatically change their jobs in Forbes - a good article, written for a lay audience.
- High-performance medicine: the convergence of human and artificial intelligence by Eric Topol - a comprehensive, academic review of the role AI will play in medicine
A video recording of a presentation I gave on the subject:
Many thanks to Dr James Hartley and Dr Gopal Kotecha for their feedback and suggestions on this article.
Comments powered by Disqus.